In this blog post, I want to dispel a myth that’s reasonably common among students: the notion that there’s something wrong about a study that compares groups of different sizes.
There is something aesthetically pleasing about studies that compare two equal-sized groups. An experiment with two conditions with 30 participants each looks ‘cleaner’ than one with 27 participants in one condition and 34 in the other. Whatever the reasons for this aesthetic appeal may be, I’m going to argue that there’s nothing un-kosher about unequal sample sizes per se. This post is geared first and foremost to our MA students, primarily to help them get rid of the idea that they should throw away data in order to perfectly balance their datasets.
There are three main causes of unequal sample sizes: simple random assignment of participants to conditions; planned imbalances; and drop-outs and missing data. I will discuss these in order.
The random assignment of participants to the different conditions is the hallmark of a ‘true experiment’ and distinguishes it from ‘quasi-experiments’. Random assignment can be accomplished in essentially two different ways. The first technique is complete randomisation: first, sixty participants are recruited; then, half of them are randomly assigned to the control and half to the experimental condition. This technique guarantees that an equal number of participants is assigned to both conditions. The second technique is simple randomisation: for each participant that volunteers for the experiment, there’s a 50/50 chance that she ends up in the control or in the experimental condition – regardless of how large either sample already is. Simple randomisation causes unequal sample sizes: you’re not guaranteed to get exactly 30 heads in 60 coin flips, and similarly you’re not guaranteed to get exactly 30 participants in either condition.
(Note: Some refer to ‘simple randomisation’ as ‘complete randomisation’, so check how the procedures are described when reading about randomisation techniques.)
Unequal sample sizes, then, may be the consequence of using simple rather than complete randomisation. And there can be good reasons for choosing simple rather than complete randomisation as your allocation technique, notably a reduced potential for selection bias (see Kahan et al. 2015) and ease of planning (it’s easier to let the experimental software take care of the randomisation than to keep track of the number of participants in each condition as participants find their way to the lab).
Compared to complete randomisation, simple randomisation seems to have a distinct disadvantage, however: an experiment with 60 participants in total has more power, i.e. a better chance to find systematic differences between the conditions, if the participants are distributed evenly across the conditions (i.e. 30/30, complete randomisation) than if they’re distributed unevenly (e.g. 20/40). (This is assuming that the variability in both conditions is comparable.) For this reason, it’s usually much better to have 50 participants in both conditions rather than 20 in one condition and 200 in the other – even though the total number of participants is much greater in the second set-up. Simple randomisation, however, can cause such imbalances. In fact, it’s possible to end up with no participants in one of the groups.
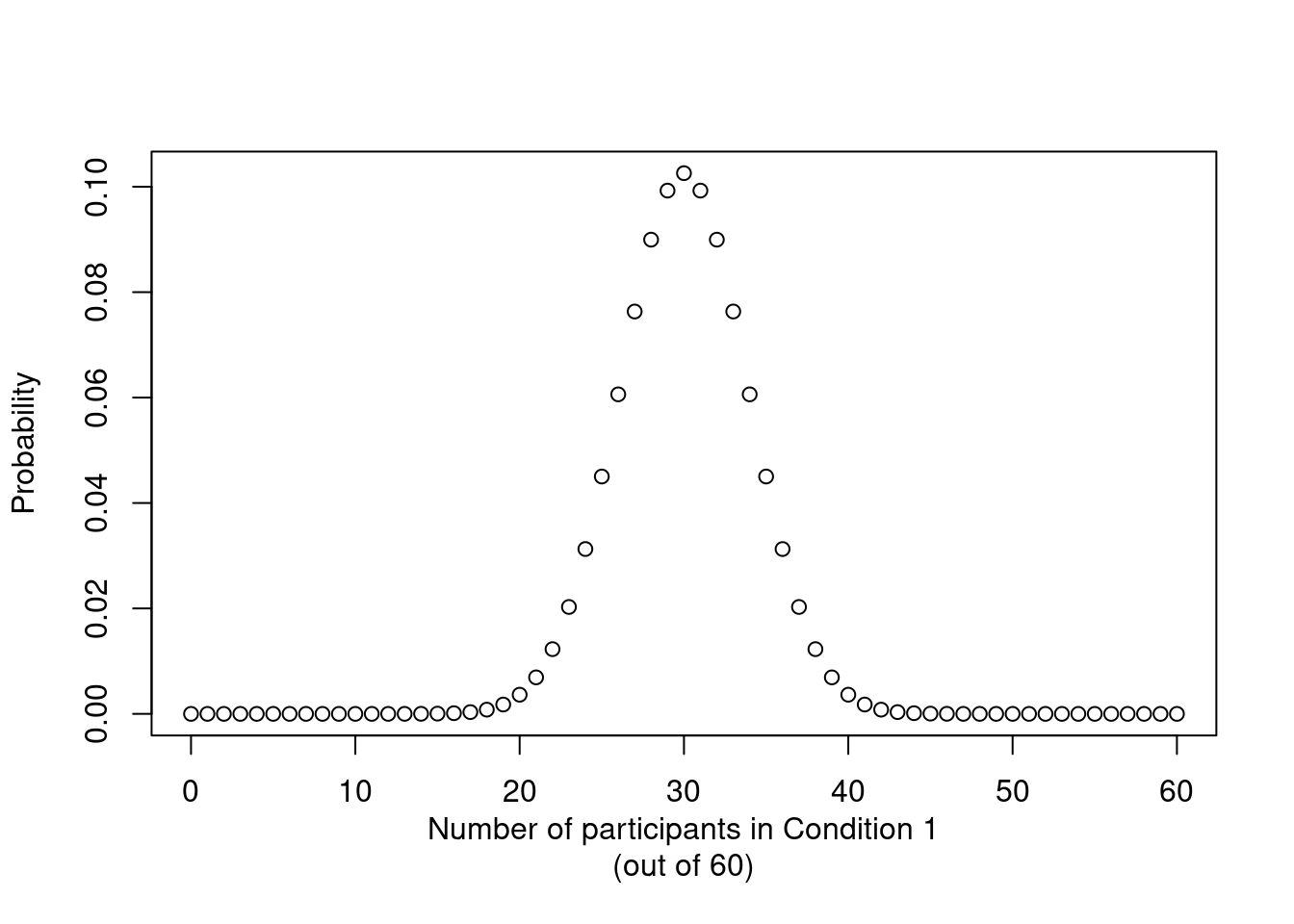
But. While stark imbalances are possible when using simple randomisation, they’re also pretty improbable. Figure 1 shows the probability of ending up with any number of participants in one condition when 60 participants are randomly assigned to one of two conditions with equal probability. As this graph illustrates, it’s highly improbable to end up with 10 participants in the first condition (and 50 in the other). In fact, in 999 out of 1,000 cases, you’ll end up with between 17 and 43 participants in each group.
Additionally, while equal-sized groups maximise statistical power, the advantage is easily overstated. An experiment with 30+30 participants has a 76% chance to detect a systematic difference of 0.7 standard deviations between the two group means; for an experiment with 20+40 participants, this probability is 71%. On average, an experiment in which 60 participants are assigned to the conditions according to a simple randomisation procedure has 75% power to detect a difference of 0.7 standard deviations. The difference in power between complete randomisation (guaranteeing equal sample sizes) and simple randomisation, then, is minimal. Table 1 compares a couple of additional set-ups, and all point to the same conclusion: the loss of power associated with simple vs. complete randomisation is negligible.
| Total number of participants | Difference (sd) | Power complete randomisation (t-test) | Power simple randomisation (t-test) |
|---|---|---|---|
| 20 | 0.7 | 0.32 | 0.30 |
| 60 | 0.7 | 0.76 | 0.75 |
| 120 | 0.7 | 0.97 | 0.97 |
| 20 | 0.3 | 0.10 | 0.10 |
| 60 | 0.3 | 0.21 | 0.21 |
| 120 | 0.3 | 0.37 | 0.37 |
Simple randomisation and the unequal sample sizes it gives rise to, then, aren’t much of a problem when comparing the means of two groups. For more complex (factorial) designs, however, they do present some complications. Specifically, cell size imbalances in factorial designs force the analyst to decide whether the effects should be estimated by means of Type I, Type II or Type III sums of squares (see the explanation by Falk Scholer). I don’t feel qualified to give any definite advice in this matter other than to point out the following:
In conclusion, sample size imbalances can be the result of assigning participants to conditions by means of simple randomisation. When comparing two groups, this doesn’t really present any problems. When the study has a factorial design, though, you may want to brush up on Type I/II/III sums of squares. But whatever you do, don’t throw away precious data just to make the group sizes equal.
Researchers sometimes intentionally recruit a greater number of participants in one condition than in the other. This seems to be particularly the case in quasi-experiments, i.e. studies in which the allocation of participants to condition is predetermined rather than manipulated by the researcher (e.g. comparisons of native speakers to foreign language learners). From what I can tell, the (usually tacit) reasons for such imbalances include:
So, even when the unequal sample sizes were planned and not due to simple randomisation, they may be a matter of sound reasoning and practicality rather than of poor design.
Imbalances can arise when participants drop out of the study or when data is lost due to technical glitches. These cases are different from the previous two (simple randomisation and planned imbalances) as they needn’t be due to different numbers of participants being assigned to the experiment’s conditions. Rather, at the end of the study, different numbers of participants remain there to be analysed.
When data are lost due to, say, computer malfunctions, the loss of data can reasonably be expected not to skew the study’s results by occurring more often in one condition than in the other or by primarily affecting high or low performers etc. In this case, the lost data are said to be missing completely at random. While such losses of data are unfortunate as they lead to a loss of statistical power, they’re benign in that you can just discount the missing data and run your analyses on the remaining data without introducing bias. (Alternatively, the analyst could try to impute the missing data, but that’s for another time.)
Not all missing data are missing completely at random, however. Say that an experimental study finds that children in L2 immersion classes outperform children in the control group (traditional classes) in subjects such as geography and biology. Such a finding could well be interpreted as evidence for bilingual advantages extending into scholastic performance. Now imagine that out of the 230 children starting the school year in an L2 class, 80 switched to traditional classes and dropped out of the study (35%), whereas out of the 200 children starting out in the control group, 20 went off the radar (10%). All of a sudden, the picture for L2 immersion looks bleaker: it’s plausible that it’s especially the pupils that would’ve performed poorly dropped out of the L2 immersion classes, and that the positive effect is the result of L2 immersion being more selective rather than being more effective. In such cases, the lost data are said to be not missing at random. Indeed, the very fact that more data are missing in the L2 immersion group than in the control condition is informative in its own right and should be taken into account when evaluating the efficacy of L2 immersion.
(There’s a third kind of ‘missingness’, viz. missing at random, which describes the situation in which the missingness can be accounted for by control variables.)
The main points to take away from this blog post are the following:
# Load pwr package library(pwr) # To compute power for complete randomisation, use: pwr.t.test(n = 30, d = 0.7)$power